
陳文正

陳建文
Generative adversarial network (GAN) has achieved impressive success on cross-domain generation, but it faces difficulty in cross-modal generation due to the lack of a common distribution between heterogeneous data. Most existing methods of conditional based cross-modal GANs adopt the strategy of one-directional transfer and have achieved preliminary success on text-to-image transfer. Instead of learning the transfer between different modalities, we aim to learn a synchronous latent space representing the cross-modal common concept. A novel network component named synchronizer is proposed in this work to judge whether the paired data is synchronous/ corresponding or not, which can constrain the latent space of generators in the GANs. Our GAN model, named as SyncGAN, can successfully generate synchronous data (e.g., a pair of image and sound) from identical random noise. For transforming data from one modality to another, we recover the latent code by inverting the mappings of a generator and use it to generate data of different modality. In addition, the proposed model can achieve semi-supervised learning, which makes our model more flexible for practical applications.
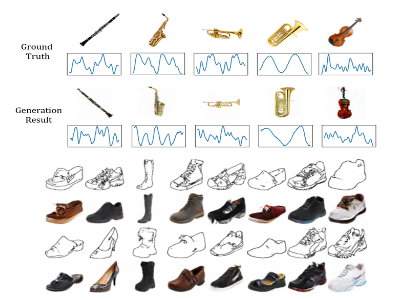
@INPROCEEDINGS{8486594, author={W. Chen and C. Chen and M. Hu}, booktitle={2018 IEEE International Conference on Multimedia and Expo (ICME)}, title={Syncgan: Synchronize the Latent Spaces of Cross-Modal Generative Adversarial Networks}, year={2018}, volume={}, number={}, pages={1-6}, abstract={Generative adversarial network (GAN) has achieved impressive success on cross-domain generation, but it faces difficulty in cross-modal generation due to the lack of a common distribution between heterogeneous data. Most existing methods of conditional based cross-modal GANs adopt the strategy of one-directional transfer and have achieved preliminary success on text-to-image transfer. Instead of learning the transfer between different modalities, we aim to learn a synchronous latent space representing the cross-modal common concept. A novel network component named synchronizer is proposed in this work to judge whether the paired data is synchronous/corresponding or not, which can constrain the latent space of generators in the GANs. Our GAN model, named as SyncGAN, can successfully generate synchronous data (e.g., a pair of image and sound) from identical random noise. For transforming data from one modality to another, we recover the latent code by inverting the mappings of a generator and use it to generate data of different modality. In addition, the proposed model can achieve semi-supervised learning, which makes our model more flexible for practical applications.}, keywords={image processing;learning (artificial intelligence);latent spaces;cross-modal generative adversarial networks;generative adversarial network;cross-domain generation;cross-modal generation;heterogeneous data;conditional based cross-modal GANs;one-directional transfer;text-to-image transfer;synchronous latent space;cross-modal common concept;novel network component named synchronizer;paired data;GAN model;synchronous data;latent code;Synchronization;Gallium nitride;Generators;Data models;Training;Generative adversarial networks;Training data;Generative adversarial network (GAN);cross-domain;cross-modal;SyncGAN}, doi={10.1109/ICME.2018.8486594}, ISSN={1945-788X}, month={July},} }