張景翔
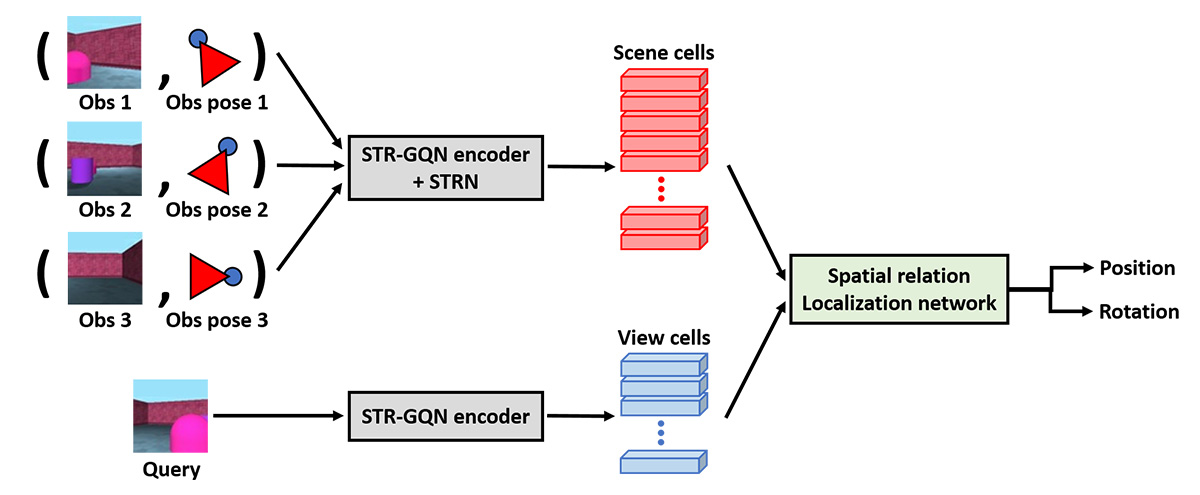
In this paper, we target on sparse visual localization which is more challenging than the classic localization task. To be more specific, sparse visual localization is a specific localization problem in which the observations have few number of samples and small overlapping viewing areas. Under these constraints, most of prior works fail to predict the accurate camera pose. With the progress of neural scene representation, the learning models can extract the implicit feature to represent the scenes without the supervision of explicit structure and geometric prior. In this work, we investigate applying the neural scene representation model to the task of sparse visual localization. We choose STR-GQN as the core scene representation model and propose the Spatial Relation Localization Network (SRLN). SRLN constructs the spatial relation codes by computing the similarity between the feature cells in world space and view space. Different camera poses have their own specific patterns of spatial relation codes and this pattern can be easily learned by a neural network. We evaluate our model using simulated environments, and the experimental results show that the proposed SRLN achieves impressive improvement over previous methods, which proves the potential of spatial relation codes and neural scene representation methods in localization tasks.