林庭葳
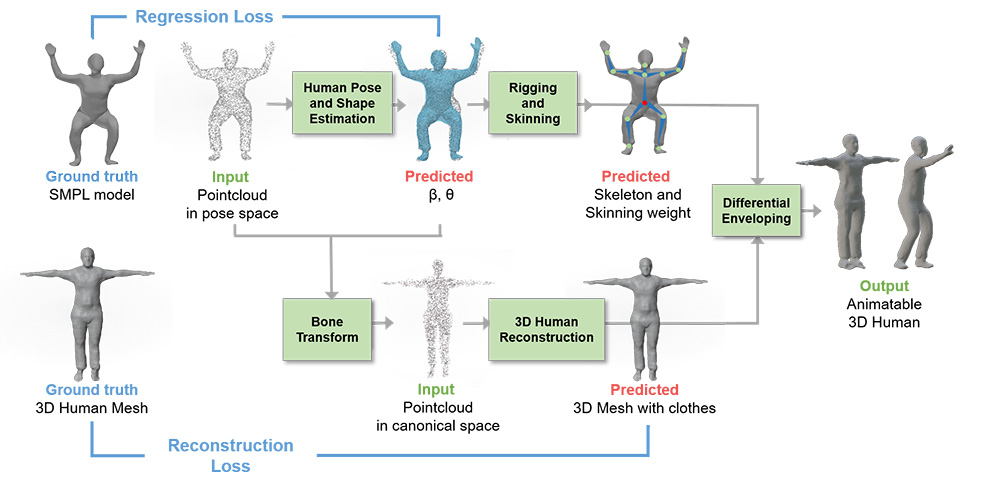
The topic of this thesis is to develop a deep learning based 3D clothed human reconstruction with skeleton binding. This thesis uses the sparse point cloud infor mation available from commercially available sensors to reconstruct a complete 3D clothed human model, and estimate the 3D model‚ joint position and the skinning weight corresponding to each vertex. In recent years, the use of neural networks for human reconstruction and skeleton binding has been used to reconstruct a static 3D model of the human body and then use an optimization algorithm to register a para metric model of the human body with additional displacement terms at each vertex to represent the human hair and clothing. However, the register step of the recon structed 3D human model may not be able to register the best pose and shape param eters, thus making the displacement not only for representing the hair and clothing of the 3D model, but also for restoring the wrong surface of the model, resulting in serious distortion of the registered parametric model. Therefore, in this thesis, we choose to fit the parametric human model with the input sparse point cloud informa tion before the 3D human model reconstruction, and convert the points from pose space to canonical space while binding them to the skeleton. In addition, extracting features from 3D point clouds in canonical space can reduce the influence of pose variation on the encoder compared to extracting features in pose space. We exper imented this model architecture on the CAPE dataset. Under this synthetic dataset, we are able to achieve 90.5 3% and 0.0143 in the evaluation of mIOU and Chamfer Distance (CD) of the decoder and 3D reconstruction results respectively, which are better than the existing state-of-the-art methods. In THuman2.0, a real dataset that does not contain any annotation data, the reconstruction results are more reliable compared to the registered parametric model.